Data driven decisions you can rely on
Sport Scientist- “Today, I’m going to start measuring stuff!” Coach- “Why?” Sport Scientist- “Because I’m a sport scientist, and to do science I need data.” Coach- “Oh, good grief, just don’t get in the way!”
In the murky world of applied sport science, where double-blinded cross over experiments never take place; coaches are never interested in research questions or data. Their only motivation for tolerating our presence is the provision of information that informs and improves their training programme. Therefore, if you want to hang around for any length of time, you’d better make sure that your data is answering the questions that the coach is asking.
This is easier said than done. There is a certain art to measuring stuff well enough to be able to make programme decisions based on the data. The first step is to get a really good understanding of the data you’re collecting. For example, lets say that you are working with a group of soccer players, and the coach has implemented a programme to improve their sprint speed. The results of testing at the beginning and completion of the programme are presented in the table below. The mean 40m sprint time of the group is 0.12 sec faster than in the previous test. Good result right?
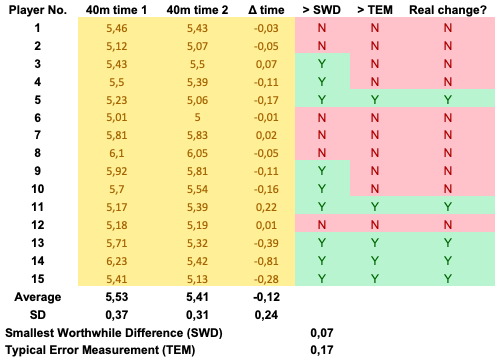
Actually, its hard to say! The first thing that needs to be determined is what is the smallest worthwhile difference (SWD) in the test that will make a difference to the players’ on-field performance. Will Hopkins (stats guru) suggests that for team sports the SWD is one fifth of the between athlete standard deviation (or a Cohen’s effect size > 0.2)1. You don’t have to do these calculations yourself, here is a link to an effect size calculator. The SWD in this example is 0.07 sec, indicating that the overall group mean has shown a small but meaningful improvement (-0.12 sec).
However, we are not out of the woods yet. A second critically important factor to consider is the reliability of the test you are using. Reliability encompasses two things; biological variation in the performance of an individual between tests, and measurement error as a result of intrinsic inaccuracy in the tester or test mechanism. Together these factors combine to form the typical error of measurement (TEM). TEM can be calculated by dividing the standard deviation for the change in measurement between two tests by the square root of two (SD of mean diff between trials/√2)2. This number will give you the sensitivity of your test, indicating the level of noise around your measurement. For the example above, the TEM is 0.16 sec, but the change in mean we have detected was only 0.12 sec. This means that we can’t confidently say that a real change has occurred because our test is not sensitive enough to detect changes at that level.
While this is a relatively simple, I use it here to explain the difficulties with a number of commonly-used, high-performance measurements. Counter movement jumps, heart rate variability and GPS measures all have large TEM’s and as a result are only sensitive to relatively large changes. Ideally, you should search for tests where the SWD > TEM, so that you can be confident that the differences you find are real. Failing this, you can improve the reliability of tests you use by using the mean rather than single tests, and look to improve the precision of measurement through more stringent protocols or better equipment.
The net result here though, is that coach still isn’t going to be very impressed hearing that the 40m sprint test isn’t sensitive enough to detect whether his players are improving! All is not lost though, the concept of individual variation in response to training means that we would expect that not all athletes will respond in the same way. The gold here is in being able to tell the coach who his programme is working for, and who might respond better to a different strategy. What the results of this analysis really reveal is that in the group of 15, only 4 players improved their 40m sprint time, 10 players showed no improvement, and 1 actually got worse. This is valuable feedback for coaches as it allows them to adjust and individualise training to achieve the intended outcomes. It might not be information that they want to hear, but it is information with a real influence on performance.
References
- Hopkins, W.G., How to interpret changes in an athletic performance test, Sportscience 8, 1-7, 2004 (sportsci.org/jour/04/wghtests.htm)
- Hopkins, W.G., Calculations for reliability, A new view of statistics, http://www.sportsci.org/resource/stats/relycalc.html, accessed 1 December 2015
Jason Tee
Coach educator and performance consultant
Coach and sports scientist with an interest in player and coach development